コマンドでSFTPによるサーバ接続【Linux】
SFTPとは
FTPのSSHバージョンです。簡単に言えばセキュアなFTPということになります。
FTPはFile Transfer Protocolの略で、ファイルをやり取りする際の取り決めです。
SSHによって暗号化された通信路を使ってファイルをやり取りすることになるので、機密情報を扱う場合や多くの企業向けシステムで利用されます。
Linuxコマンド
接続
$ sftp -i <秘密鍵のパス> -oPort="<サーバーのPort>" <公開鍵のユーザー名>@<サーバーのIP>
秘密鍵のパスは大抵「~/.ssh」フォルダに格納されると思うので、鍵の名前が「id_rsa」であれば「~/.ssh/id_rsa」となります。
サーバーのポートは、SSHの場合「22」が世界で共通のデフォルトポートですが、世界に知られた状態ではまずい、ということもあってカスタムポートを開くことが一般的です。例えば22600などを指定します。
鍵の作成
下記のようなコマンドで公開鍵と秘密鍵を作成したら、そのユーザー名を上記接続の際に使用します。
$ ssh-keygen -t <暗号方式(rsaなど)> -f <鍵のパス(ファイル名称も拡張子なしで指定)> -C <ユーザー名>
作成した公開鍵の内容は、接続先サーバーの~/.ssh/authorized_keysに追記されている必要があります。それによって、接続元を認識しているわけです。秘密鍵を接続の際に渡すことで、接続が安全であることを確認しています。
ファイルのアップロードとダウンロード
sftp接続を完了した状態を前提に話します。
手順があります。
【アップロードの場合】
1:
sftp> cd <ディレクトリまでのパス>
2:
sftp> put <ファイル名>
【ダウンロードの場合】
1:
sftp> cd <ディレクトリまでのパス>
2:
sftp> get <ファイル名>
また、コマンドを実行している「ローカル」のカレントディレクトリを下記コマンドで確認できます。
sftp> lpwd
Cloud SchedulerでHTTPエンドポイントを叩く【GCP】
Cloud Schedulerとは
Jobを作成する
GCPコンソール(画面)から行うか、gcloudコマンドを利用します。
gcloudコマンドでしか設定できないものも多いので、コマンドでの設定をお勧めします。
なお、コマンドでしか設定できない内容の場合、コマンドで設定した後にコンソール画面から更新してしまうと、
コマンドでしか設定できない内容が失われましたので、注意が必要です。
サンプル
下記サンプルは
- HTTP"http://31.20.90.11:3001/tests"を毎朝9時(cron指定)にキックする
- headerに
A-KEY=12を指定 - タイムゾーンはAsia/Tokyo
- 名前はthis_is_job_name
というjobを作るコマンドです。
$ gcloud scheduler jobs create http this_is_job_name --schedule="00 9 * * *" --uri="http://31.20.90.11:3001/tests" --headers A-KEY=12 --time-zone="Asia/Tokyo"
Headersで設定した内容はコマンドでしか設定できません(2019年11月時点)。さらにlogに出力されないため、確認することはできません。(
公式より)
Docker on Google Compute Engine【GCP】
GCPを使って外部IPを立てる選択肢
外部IPを立てるにはいくつか選択肢があります。
- Google Kubernetes Engine(GKE)を使う
- Google Compute Engine(GCE)を使う
GKEを使う場合、Kubernetesを使うので外部IPが動的になります。
GCEを使う場合、IPを固定にすることが可能です。クライアント先のサーバーにアクセスするなど、固定IPが求められるケースではGCEを使うことになるかもしれません。固定IPを実現するために、Cloud NATという選択肢もあります。
GCEで固定IPを実現する方法は2つあります。
- Dockerのコンテナを使用する
- Linux OSを使用する
ここではDockerによる方法のうち、つまづきやすいポイントを紹介します。
方法はGCPの公式、もしくは検索すればわかりやすい記事がたくさんあるのでそちらを参照ください。
Docker on GCEのつまりポイント
- ポートの開放
- VMインスタンスを再起動すると、外部IPが変わる
- Volume をマウントする
- 「ホスト」のパスはGCEのインスタンス上のパス
- 「ホスト」に対してファイルなどをアップロードする際、gcloudコマンドの他、GCPコンソールから実行できる
- 「マウント」のパスは、root(/)を指定できない。これはDockerのルール。Dockerfile上で
RUN mkdir ~でdirを作ってそれを使うか、tmpなどコンテナ既存のdirを使う
また、SSH接続を使って外部IPにアクセスする際、秘密鍵をVMインスタンスで扱うことがあるかと思います。
公開鍵方式でSSH ハンドシェイクのエラーになるときは、接続先の誤りや秘密鍵に問題があります。catコマンドで確認して一見問題ないように思えても、秘密鍵を置き換えてみると成功したケースがあったので、秘密鍵の置き換えも視野に入れておいた方がいいかもしれません。
MySQLのインデックス
インデックスとは何か
テーブルの中身を検索するときに、任意のカラムの値で検索しやすいようにしておくための機能です。
たとえばnameというカラムを持つメンバーリストのテーブルがあるとします。
それはid順では並んでいますが、name順では並んでいません。
where name=Yamadaでselectすると、テーブル内の行全てを順に辿っていって、条件に合致するものを抽出していきます。テーブルに保存されている行数が多いほど、無駄な捜索が生まれることは想像できます。
nameに対してインデックスを指定すると、idとnameをカラムとして持つインデックステーブルが作成されます。しかもこのテーブルはnameの昇順に並んでいるので、where name=Yamada で検索した場合、先ほどよりも無駄な捜索がグッと減る可能性が高いです。
ただし、インデックスを指定するということは、インデックステーブルを作成する、ということであり、元のテーブルへの追加・更新・削除をする場合には、インデックステーブルにも同じ作業をする必要があります。インデックスの数が増えるだけ、その作業は増えていきます。
なので、使う可能性や頻度が低いようなインデックスをむやみやたらに指定することは避けたほうがいいでしょう。
データアクセスの仕組み
MySQLでは、SQLが実行されたあと、次のような手順で、データにアクセスされます。
- SQLの実行
- データベースエンジンへアクセス
- ストレージエンジンへアクセス
データベースエンジンでは、オプティマイザと呼ばれる(プランナとも呼ばれる)機能がSQLをパースします。
実行されたSQLが、SelectなのかUpdateなのかなどの命令の解析、インデックスが指定されているか、指定されている場合はそのインデックスを使用したほうがいいのか、またテーブルの結合方法を決めます。いわゆる「実行計画」です。
解析されたSQLを元にストレージエンジンへアクセスします。
ストレージエンジンは、テーブルをどのようなファイル形式で保存しているのか、という情報を持っています。
テーブルの情報は、1つのファイルで構成されているとは限りません。サイズなどによって複数ファイルに分割されて保存されていることもあります。テーブルの情報にアクセスするには、そのテーブルがどのように、そしてどこに保存されているかを知る必要があります。その情報を提供する役目を果たすのがストレージエンジンです。
ストレージエンジンにはいくつか種類がありますが、MySQLではテーブルごとにストレージエンジンを指定することができます。Create時のENGINE句、またはALTER文でストレージエンジンを変更することができます。
ストレージエンジンを明示的に指定することは稀かもしれません。指定をしなくてもデフォルトで指定されます。MySQL5.5以降では、デフォルトに指定されるのはInnoDBです(5.4以前ではMyISAM)。
ストレージエンジンにはそれぞれ特性があり、アプリケーションの要件に応じて適切なストレージエンジンを選択することで、パフォーマンスを向上できる可能性があります。
MySQLによってデフォルトに指定されるInnoDBにも優れた点があり、またどのようにSQL文を発行すると最大限に活用できるのかが、こちらにまとめられています。
MySQLでインデックスを使う
インデックスを使うには、SQL上で下記のkeyを指定します。単独でも、組み合わせてもOKです。
- key
- primary key
- unique key
- foreign key
primary keyは主キーを指定します。uniquey keyに指定された組み合わせは、そのテーブル内で重複ができません。foreign keyは外部制約キーです。deleteなどの指定によって、参照されている親テーブルのカラムの同じデータを削除することができなくなったりします。
たとえば、a、b、cの3つのカラムがあるテーブルで、次のようなkeyが指定されている場合、
key: b unique key: a、b
where句を次のように指定すればインデックスの効果が発揮されます。
where a = 1 and b = 1
where a = 1
where b = 1
keyは順序が大切なので、下記に指定した場合インデックスは効きません。
where b = 1 and a = 1
keyの指定が下記である場合、
unique key: a、b
下記はインデックスが効きません。
where b = 1
MySQL Explain
指定したIndexが効いているかなど、SQLのチューニングをする上で役に立つのが、explainです。
実行したいSQL文の最初に explain と記述するだけです。
$ explain select * from table_a where a = 1;
explain結果のチェックポイントは下記3つです。
- id、select_type、tableフィールド
- どのテーブルが、どの順序でアクセスしたかを知ることができます。
- type、key、ref、rowsフィールド
- 各テーブルからどのようにレコードが取得されたかがわかります。
- どのテーブルへのアクセスがもっとも重いかがわかります。
- Extraフィールド
- オプティマイザの挙動を確認することができます。
- それぞれのテーブルがなぜその順序でアクセスされているかがわかります。
- explain結果の全体見通しを立てるため、最初に確認すると良いでしょう。
各フィールドにはそれぞれ決められた値が存在するので、explainの実行結果に応じて調べ、覚えていくのが良いかと思います。
こちらの記事が有名です。
インデックスがなぜ重要か
インデックスを効果的に使うことができれば、1つのクエリにかかるコストを抑えることができます。
ストレージエンジンの性能には限界があります。ストレージエンジンの1秒あたりに処理できる行数が100万行である場合、仮に1つのクエリが100行取得するとすると、1秒間に最大1万回のクエリを実行できます。
限られた時間内での最大可能実行数は、アプリケーションレベルによって重要度が変わりますが、1回のクエリにかかる時間はどのようなレベルのアプリケーションであっても人が体感できる場合にはできるだけ速いほうがいいです。
MySQLのクエリ実行を速くするためにできることは、こちらでも紹介されている通り、クエリのチューニングだけではありません。しかし、最低限無駄のないクエリを記述しておくこと、テーブルを設計する際にクエリを実行しやすいかなどをよく考えることは大切かと思います。
参考
漢(オトコ)のコンピュータ道: MySQLのEXPLAINを徹底解説!!
漢(オトコ)のコンピュータ道: MySQLを高速化する10の方法
[ThinkIT] 第1回:MySQLストレージエンジンの概要 (1/3)
MySQL :: MySQL 5.6 リファレンスマニュアル :: 14.1.1 デフォルトの MySQL ストレージエンジンとしての InnoDB
SQLトランザクション【Go】
Goでのトランザクションの構築方法と、トランザクションの利用ケースについて触れます。
MySQLなどのデータベースにアクセスする際、Goではdatabaseパッケージを使うことができます。
databaseパッケージを用いてトランザクションを構築するには、Txを使います。
※下記の例では、SQLビルダーのSQuirrelを名前空間"sq"と指定して利用しています。
※modelの定義を省略しています。
※クリーンアーキテクトによる実装をモデルとしており、SQL操作をするrepositoryとビジネスロジックを記述するservice層に分かれているコードを無理やり1つにまとめています。
// 共通処理を関数化
func ConnectDB() *sqlx.DB {
// 任意の設定内容を指定
c := mysql.Config{
DBName: os.Getenv("MYSQL_DATABASE"),
User: os.Getenv("MYSQL_USER"),
Passwd: os.Getenv("MYSQL_PASSWORD"),
Addr: os.Getenv("MYSQL_ADDRESS"),
Net: "tcp",
Loc: util.TimeZoneJST,
ParseTime: true,
AllowNativePasswords: true,
}
dsn = c.FormatDSN()
db, err := sqlx.Open("mysql", dsn) // mysqlを開く
if err != nil {
log.Fatalf("Could not connect to mysql: %s", err)
}
if err := db.Ping(); err != nil {
log.Fatalf("Could not connect to mysql: %s", err)
}
}
func Transact(ctx context.Context, db Beginner, txFunc func(Tx) error) (err error) {
defer func() {
if p := recover(); p != nil {
if err := tx.Rollback(); err != nil {
l.Error("database: failed to rollback", zap.Error(err))
}
panic(p)
}
if err != nil { // txFunc(tx)が返すerror
if err := tx.Rollback(); err != nil {
l.Error("database: failed to rollback", zap.Error(err))
}
} else {
return tx.Commit()
}
}()
return txFunc(tx)
}
// service ビジネスロジックを記述
type member struct {
mRepo repository.Member
db database.Runner
}
func (s *member) Wrapper(ctx context.Context,whosid int64, whosname string) error {
return Transact(ctx, s.db, func(tx database.Tx) error {
return s.mRepo.Update(ctx, tx, &model.Member{
ID: whosid,
Name: whosname,
})
})
}
// repository SQL操作を記述
func (r *member) Update(ctx context.Context, who *model.Member) error {
db := ConnectDB() // DBと接続
defer db.Close()// 必ず接続を閉じる
tx, err := db.Begin(ctx) // トランザクションを開始
if err != nil {
return err
}
q, attrs, err := sq. // SQuirrelを利用
Update("members").
SetMap(sq.Eq{
"name": who.Name,
}).
Where(sq.Eq{
"id": who.ID,
}).
ToSql()
if err != nil {
return err
}
// ここで、sqlに関するlogの出力をした方が良いでしょう
if _, err := sql.ExecContext(ctx, q, attrs...); err != nil {
return err
}
return nil
}
上記は更新系SQL、しかも単文の例でしたが、たとえばSelectの結果を用いてUpdateやInsertをする場合にもトランザクションを構築します。
その際は、SelectメソッドとUpdateメソッドを内包するラッパーメソッドを作成することになると思います。Selectメソッド、Updateメソッドがsql処理を行うだけのメソッドだと仮定するならば、Selectメソッドの引数はdatabase.Txではなく、database.Queryerを用います。Select SQL自体には明示的にトランザクションを構築する必要がないためです。Select SQL文にはfor updateを用いて、抽出対象行を排他ロックすることでしょう。
SelectやUpdateのSQLを組み合わせる以外にも、例えば会員登録直後に送信する、24時間有効なリンクを貼った確認メールなどでもトランザクションが使えます。テーブルへの登録、更新処理と合わせてメール送信が完了しない場合にはロールバックをして、会員登録を無かったことにするのです。会員登録を済ませるにはどちらも必須条件ですから、トランザクションで囲むことが有効です。
Beginを明示的に指定してトランザクションを開始しない場合、MYSQLでは、Auto Commitの設定値が有効であれば、最初のSQLが発行されたタイミングでトランザクションが開始されます。これはSelect単文、しかもfor updateでない場合でもです。
Testコードを書く場合のテクニック
SQL操作部分のテストコードを書く場合も、いくつかのテストケースを用意するでしょう。
for文を回して、テストケースの数だけまとめて処理を実行することになるかと思いますが、各テストケースの内容が他のテストケースに影響を与えないように、各テストケースの実行完了後には、それが実行される前の状態に戻しておいたほうが確認がしやすいです。
そんな時は、意図的にエラーを起こすことで、トランザクションのロールバックを利用します。
先ほどのTransact関数では、引数として渡した関数がerrorを返す場合、ロールバックされる仕様になっています。各testcaseが終了するたびにerrorを返すことで、処理直前の状態に戻すことができます。
func Test_customizeType_Update(t *testing.T) {
dbConn, teardown := GetTestDBConn() // テスト用のDB接続を行う任意の関数
defer teardown()
// 必要に応じてテーブルに必要なデータを挿入する処理を記述
db := database.NewRunner(dbConn)
type args struct {
ctx context.Context
member *model.Member
}
cases := map[string]struct {
args args
err error
success bool
}{
"Success": {
// テストケース
},
"Duplicate name": {
// テストケース
},
...
}
for testname, testcase := range cases {
t.Run(testname, func(t *testing.T) {
...
Transact(testcase.args.ctx, db, func(tx database.Tx) error {
err := repo.Update(testcase.args.ctx, tx, testcase.args.member)
if !assert.Equal(t, testcase.err, errors.Topmost(err)) {
t.Logf("%#v failed: %#v", testname, err)
}
testContains(testcase.args.ctx, repo, t, tx, testcase.args.customizeType, testcase.success) // Updateした結果がテーブルレコードに含まれるかをチェックする任意の関数
return fmt.Errorf("rollback") // errorを必ず発生させて、rollbackさせる
})
})
}
}
参考
MySQLのトランザクション制御がキモい話 - なからなLife
実行時の関数名やファイルパス、行数を取得する【Go】
runtimeパッケージのCallerを用いて取得することができます。
package main
import (
"runtime"
"fmt"
)
func main() {
pc, pwd, line, ok := runtime.Caller(0)
fn := runtime.FuncForPC(pc)
fmt.Println(pc, pwd, line, ok, fn.Name())
}
runtime.Caller()の引数はint型のskipと定義され、gorutineのスタック上に実行順で積み上げられた関数から、どれを取得するかを指定します。
0がCaller()呼び出し元の関数です。上記例では、ついでmainパッケージのmain関数、ついでruntimeパッケージのmain関数、runtimeパッケージのgoexit関数です。
例えば下記のように、複数の関数を実行させた場合、
package main
import (
"runtime"
"fmt"
)
func main() {
test()
}
func test() {
pc, pwd, line, ok := runtime.Caller(0)
fn := runtime.FuncForPC(pc)
fmt.Println(pc, pwd, line, ok, fn.Name())
}
0がmain.test、1がmain.main、2がruntime.main、3がruntime.goexitとなります。
runtime.goexitはgorutineを終了させる関数です。
runtime.Caller()の第1返り値は、pc、プログラムカウンターで、次に実行する命令を保存したメモリ上のアドレスを保存したものです。
runtime.FuncForPC()の引数に与えて実行することで、関数の情報を取得することができ、Name()を使って、関数名を取得しています。
第2返り値はpwdで、その関数が記述されたファイルの現在地(ファイルパス)です。
第3返り値は Caller()が記述されている行を示します。
Caller()が内容を取得できなかった場合、第4返り値がfalseになります。
これらはアプリケーションのログ出力に役立ちます。
Go × Cloud Functionsでメール送信機能を開発【Go】【GCP】【CI/CD】
概要
GoとCloud Functions、さらにSend Gridというメールサービスを使って、HTTPリクエストからメールを送信できる機能を開発します。
さらに、関数を記載したGithubリポジトリへmasterブランチへのマージがあれば、Cloud Funcitonsへデプロイして関数を更新します。
使用技術
- Go
- Cloud Functions (HTTP関数)
- Send Grid
- Cloud Build
Send Gridの登録
新規登録後、公式ドキュメントに従い、API_KEYを発行し、控えておきます。
メール機能の開発
SendGrid for Goのライブラリを使用して、メールを送信する関数を開発します。
まずはRequest Bodyとして受け取る、メール送信に必要な情報を格納するstructを定義します。
type postParam struct {
From string `json:"from" validate:"required,email"`
FromName string `json:"from-name" validate:"required"`
To string `json:"to" validate:"required,email"`
ToName string `json:"to-name" validate:"required"`
Subject string `json:"subject" validate:"required"`
PlainContent string `json:"plain-content" validate:"required"`
HTMLContent string `json:"html-content" validate:"required,html"`
}
ライブラリvalidatorを使って、受け取る情報を検証しています(validate)。
Cloud Functionsでは、変数をグローバル定義にすることで、その変数の値がキャッシュされ、二回目以降の関数呼び出しで再利用されます。
これを利用して、Send Gridとの接続を確立する変数をグローバルスコープに定義するとともに、
init()関数で、その接続を確立します。init()関数はコールドスタートの時のみ実行されます。これによって、コストの高い外部との接続を関数の都度実行する必要がなくなります。
API_KEYはデプロイ時に設定する環境変数から読み取っています。
var client *sendgrid.Client
func init() {
apiKey := os.Getenv("SENDGRID_API_KEY")
if apiKey == "" {
panic("empty SENDGRID_API_KEY")
}
client = sendgrid.NewSendClient(apiKey)
}
メール機能の本丸です。
func SendMail(w http.ResponseWriter, r *http.Request) {
//CORS
w.Header().Set("Access-Control-Allow-Origin", "*")
w.Header().Set("Access-Control-Allow-Methods", "POST")
w.Header().Set("Access-Control-Allow-Headers", "Content-Type")
if r.Method == http.MethodOptions {
w.WriteHeader(http.StatusNoContent)
return
}
if r.Method != http.MethodPost {
http.Error(w, "Method should be POST.", http.StatusMethodNotAllowed)
fmt.Printf("You requested method %s, but method should be POST.", r.Method)
return
}
var param postParam
if err := json.NewDecoder(r.Body).Decode(¶m); err != nil {
http.Error(w, "Invalid request body", http.StatusBadRequest)
fmt.Printf("Invalid request body: %s", err.Error())
return
}
v := validator.New()
if err := v.Struct(param); err != nil {
http.Error(w, "Validation error.", http.StatusBadRequest)
errMsg := []string{}
for _, err := range err.(validator.ValidationErrors) {
var errField string
// deal with err
switch err.Field() {
case "From":
errField = "'from (送信元アドレス)'"
case "FromName":
errField = "'from-name (送信元名)'"
case "To":
errField = "'to (送信先アドレス)'"
case "ToName":
errField = "'to-name (送信先名)'"
case "Subject":
errField = "'subject (件名)'"
case "PlainContent":
errField = "'plain-content (プレーンテキスト本文)'"
case "HTMLContent":
errField = "'html-content (HTML形式本文)'"
}
errMsg = append(errMsg, fmt.Sprintf("%s validation error. Specified: %s, Actual: %s", errField, err.Tag(), err.Value()))
}
fmt.Printf("Validation error: %s", strings.Join(errMsg, "\n"))
return
}
from := mail.NewEmail(param.FromName, param.From)
to := mail.NewEmail(param.ToName, param.To)
message := mail.NewSingleEmail(from, param.Subject, to, param.PlainContent, param.HTMLContent)
response, err := client.Send(message)
if err != nil {
http.Error(w, "SendGrid send error.", http.StatusServiceUnavailable)
fmt.Printf("SendGrid send error: %s", err.Error())
return
}
for k, v := range response.Headers {
for _, vv := range v {
w.Header().Add(k, vv)
}
}
w.WriteHeader(response.StatusCode)
fmt.Fprintln(w, response.Body)
}
序盤でCORSの対応と、プリフライトリクエストの対応、メソッドの確認を行なっています。
jsonメソッドを用いて、クライアントから送信されたRequest Bodyの値を定義したstructにデコードしています。
その際に、validateに定義した規則に従っていない値ならば、その内容に応じたエラーを返します。
なお、http.Errorを返すのは非常に重要です。
こちらにも書かれている通り、エラーレスポンスを返さない限り、Cloud Functionsは、タイムアウトするまで関数を実行し続け、その数だけ課金され続けてしまう可能性があります。
fmt.Printf()などで出力したログは、GCPコンソールのLogging UIやgcloudコマンドで確認することができます。
メール送信の記述はSend Gridの公式ドキュメントでも紹介されている一般的な書き方です。
ただし、Go版ではIssueにも上がっているように、plain text contentを必ず指定する必要があります。指定しない場合、エラーになるので注意してください。
Send GridのSend()メソッドは下記の型のResponseを返します。
type Response struct {
StatusCode int // e.g. 200
Body string // e.g. {"result: success"}
Headers map[string][]string // e.g. map[X-Ratelimit-Limit:[600]]
}
これらをhttp.ResponseWriterの各フィールドに書き込みます。
for k, v := range response.Headers {
for _, vv := range v {
w.Header().Add(k, vv)
}
}
w.WriteHeader(response.StatusCode)
fmt.Fprintln(w, response.Body)
Headersの型がmap[string][]stringなので、2回for文を回す必要があります。
w.Header().Add(key, value)を使うことで、同じものを上書きしてしまうことなく、追加していくことができます。
StatusCodeはWriteHeader()メソッドを使います。
Bodyに関してはfmt.Fprintlnを使っています。
Body内容を書き込むには下記方法もありますが、
w.Write([]byte(response.Body))
この方法だと、[]byte()によって、変換に伴うメモリアロケーションが生じてしまいます。
fmt.Fprintf()は、内部でメモリを再利用しているため、メモリ効率に優れています。
全文を記載します。
今回はCloud Functionsへデプロイすることを想定しています。
package名は任意で構いません。mainパッケージも必要ありません。(というよりも、mainを指定できません。)
packageを複数用意して、デプロイする関数内で外部関数を参照することも可能ですが、
Cloud Functionsにデプロイする、という目的上、なるべくシンプルにした方が良いかもしれません。
package mail
import (
"encoding/json"
"fmt"
"net/http"
"os"
"strings"
"github.com/sendgrid/sendgrid-go"
"github.com/sendgrid/sendgrid-go/helpers/mail"
validator "gopkg.in/go-playground/validator.v9"
)
type postParam struct {
From string `json:"from" validate:"required,email"`
FromName string `json:"from-name" validate:"required"`
To string `json:"to" validate:"required,email"`
ToName string `json:"to-name" validate:"required"`
Subject string `json:"subject" validate:"required"`
PlainContent string `json:"plain-content" validate:"required"`
HTMLContent string `json:"html-content" validate:"required,html"`
}
var client *sendgrid.Client
func init() {
apiKey := os.Getenv("SENDGRID_API_KEY")
if apiKey == "" {
panic("empty SENDGRID_API_KEY")
}
client = sendgrid.NewSendClient(apiKey)
}
func SendMail(w http.ResponseWriter, r *http.Request) {
//CORS
w.Header().Set("Access-Control-Allow-Origin", "*")
w.Header().Set("Access-Control-Allow-Methods", "POST")
w.Header().Set("Access-Control-Allow-Headers", "Content-Type")
if r.Method == http.MethodOptions {
w.WriteHeader(http.StatusNoContent)
return
}
if r.Method != http.MethodPost {
http.Error(w, "Method should be POST.", http.StatusMethodNotAllowed)
fmt.Printf("You requested method %s, but method should be POST.", r.Method)
return
}
var param postParam
if err := json.NewDecoder(r.Body).Decode(¶m); err != nil {
http.Error(w, "Invalid request body", http.StatusBadRequest)
fmt.Printf("Invalid request body: %s", err.Error())
return
}
v := validator.New()
if err := v.Struct(param); err != nil {
http.Error(w, "Validation error.", http.StatusBadRequest)
errMsg := []string{}
for _, err := range err.(validator.ValidationErrors) {
var errField string
// deal with err
switch err.Field() {
case "From":
errField = "'from (送信元アドレス)'"
case "FromName":
errField = "'from-name (送信元名)'"
case "To":
errField = "'to (送信先アドレス)'"
case "ToName":
errField = "'to-name (送信先名)'"
case "Subject":
errField = "'subject (件名)'"
case "PlainContent":
errField = "'plain-content (プレーンテキスト本文)'"
case "HTMLContent":
errField = "'html-content (HTML形式本文)'"
}
errMsg = append(errMsg, fmt.Sprintf("%s validation error. Specified: %s, Actual: %s", errField, err.Tag(), err.Value()))
}
fmt.Printf("Validation error: %s", strings.Join(errMsg, "\n"))
return
}
from := mail.NewEmail(param.FromName, param.From)
to := mail.NewEmail(param.ToName, param.To)
message := mail.NewSingleEmail(from, param.Subject, to, param.PlainContent, param.HTMLContent)
response, err := client.Send(message)
if err != nil {
http.Error(w, "SendGrid send error.", http.StatusServiceUnavailable)
fmt.Printf("SendGrid send error: %s", err.Error())
return
}
for k, v := range response.Headers {
for _, vv := range v {
w.Header().Add(k, vv)
}
}
w.WriteHeader(response.StatusCode)
fmt.Fprintln(w, response.Body)
}
Cloud Functionsへ関数を登録する
Cloud Functionsの基本的な使い方はこちらに記載しました。
GoでCloud Functionsを使うには、go.modが必要です。
Go1.12では標準搭載となりますが、それ以前のver.を使っている場合には、こちらを参考にしてください。
go.modファイルがあることを確認し、先ほどのSendMail関数を記述したファイルと同じ階層で下記のようなコマンドを実行します。
$ gcloud functions deploy SendMail --runtime go111 --set-env-vars SENDGRID_API_KEY=<YOUR_API_KEY> --trigger-http --region asia-northeast1
SendMailをデプロイするにあたって、実行環境にGo 1.1.1を指定し、先ほどのコードで指定した"SENDGRID_API_KEY"を環境変数として、発行したAPI_KEYを指定します。
最後にリージョンを東京に指定していますが、明示的に指定しない場合、usリージョンになってしまうので、注意が必要です。当然のことながら、関数の呼び出し元に近いリージョンを指定することが速度的にも重要です。
Cloud Buildを使って、CDフローを整備する
関数を記載したファイルをソース管理ツールにアップロードして管理するかと思います。
関数に関係する部分に変更があったら、自動的にデプロイするフローを用意した方が楽です。
(Cloud Functionsの仕組みは、関数を含むファイルをzip形式でアップロードするというものなので、関数を更新する場合は、その後に再度デプロイをする必要があります。)
Cloud Buildの使い方はこちらで紹介しています。
今回はcloudbuild.yamlを使います。
steps:
- name: 'gcr.io/cloud-builders/gcloud'
args: ["functions", "deploy", "SendMail", "--runtime go111", "--set-env-vars SENDGRID_API_KEY=${_SENDGRID_API_KEY}", "--trigger-http"]
nameにgcloudを使うことを明記します。
argsは、先ほど記したgcloudコマンドと同じ内容です。
API_KEYは代入変数を指定しており、GCPのコンソール画面(Cloud Build)で、_SENDGRID_API_KEYを指定しておきます。
環境変数やリージョンは、関数名が同じであれば、都度指定する必要はないのですが、何らかの影響で、関数が削除される自体も予想できます。継続的な開発を考える上でもAPI_KEYを毎回指定するようにしています。
このcloudbuild.yamlファイルをこのプロジェクトのルートディレクトリに配置し、GCPのコンソール画面で実行対象ファイルに指定します。
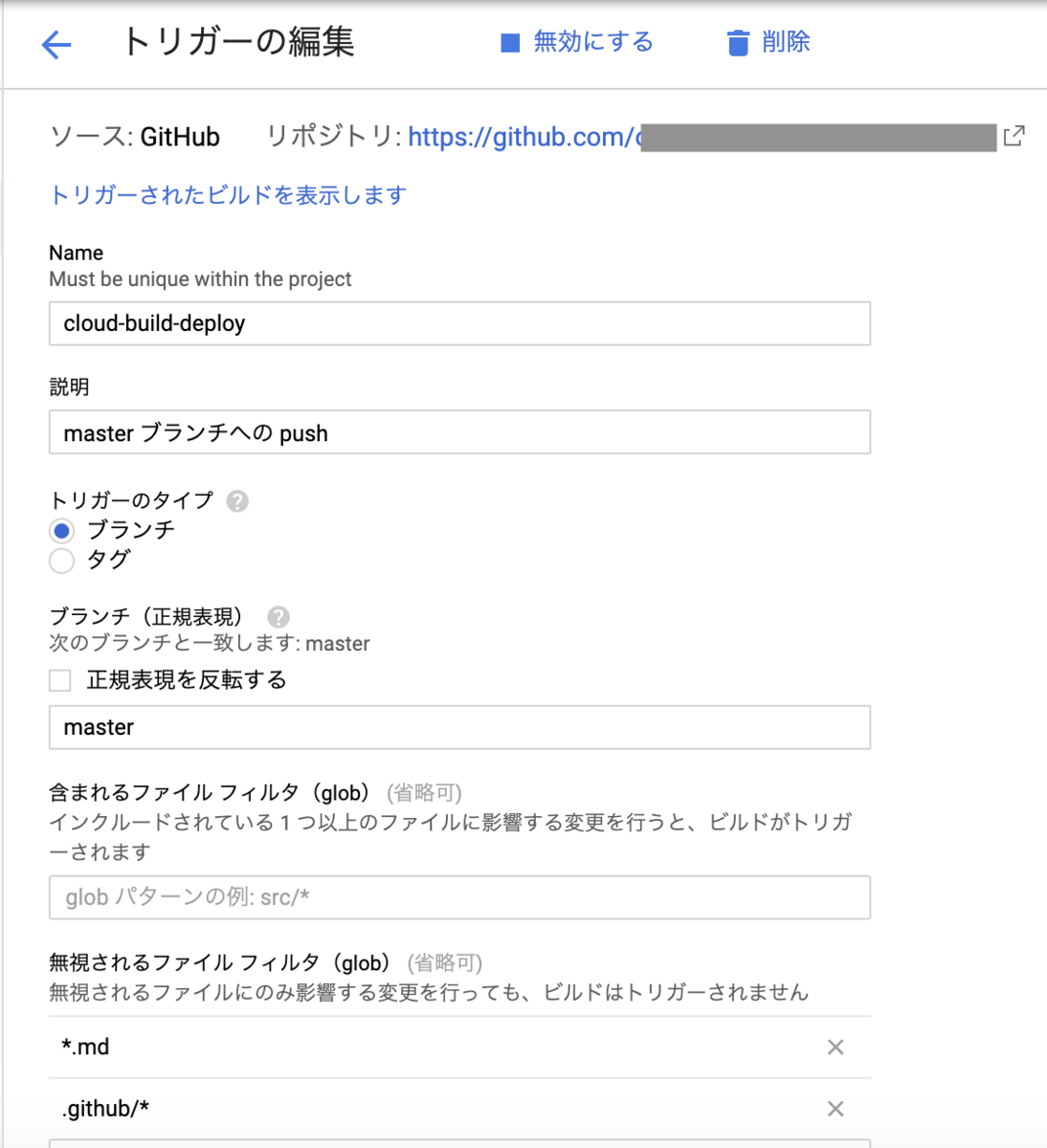
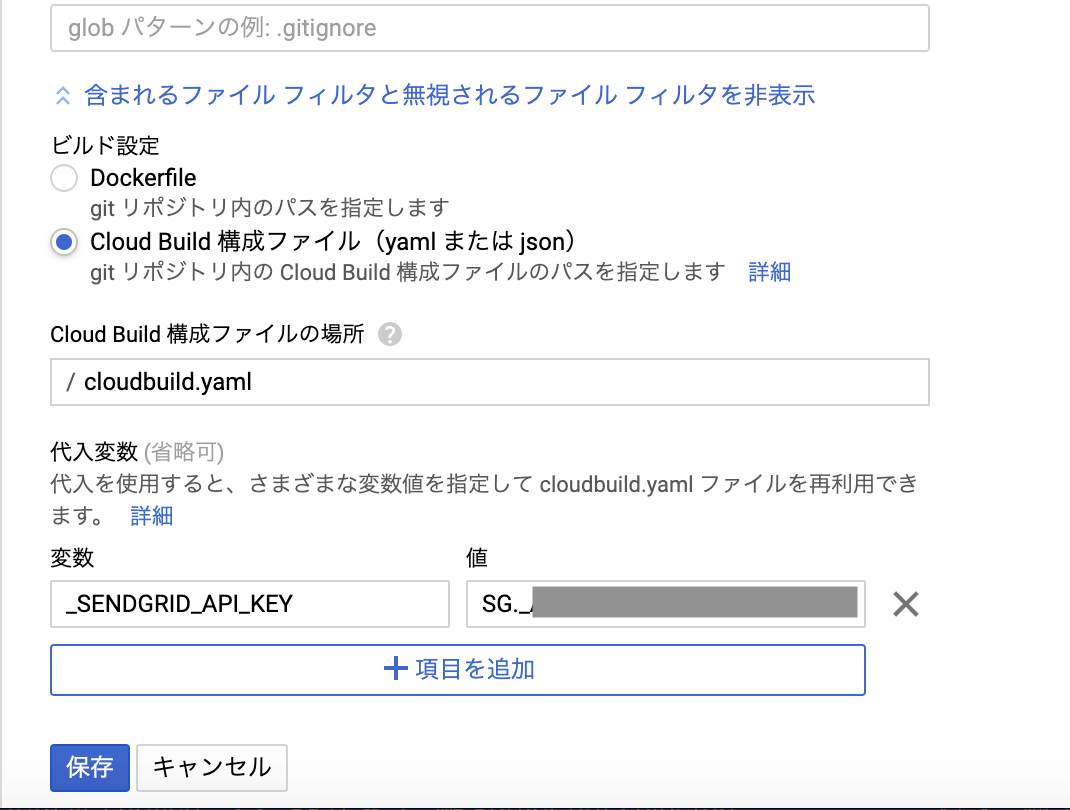
これで、masterブランチにマージされると、同時に関数がCloud Functionsにデプロイされるようになりました。
ただし、セキュリティの観点から、API_KEYを他の方法で管理するなど工夫は必要かもしれません。
参考
Cloud Functions公式ドキュメント
Cloud Build公式ドキュメント
Send Grid公式ドキュメント
Send Grid for Go Github